C:\Users\jis00\Research\gpuRIR\setup.py:32: DeprecationWarning: distutils Version classes are deprecated. Use packaging.version instead.
cmake_version = LooseVersion(re.search(r'version\s*([\d.]+)', out.decode()).group(1))
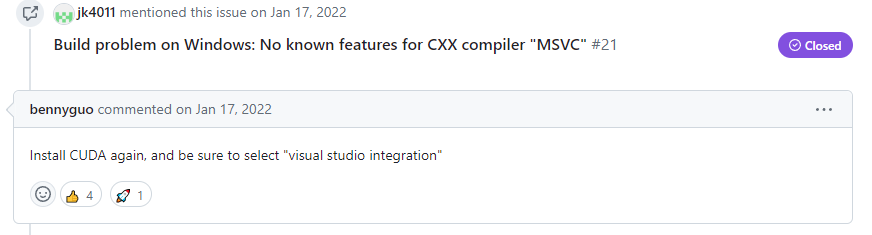
CMake Error at CMakeLists.txt:5 (project):
Generator
Visual Studio 17 2022
could not find specified instance of Visual Studio:
C:/Program Files/Microsoft Visual Studio/2022/Community
잘 알려져있고 가장 강력한 speech analysis technique 중 하나로 discrete-time speech production model의 parameter들을 추정하거나 낮은 bit rate으로 speech를 representing하여 전송 혹은 저장하는데 사용됩니다.
이름(linear predictive coding)에서 알 수 있듯이 본래는 speech processing 분야에서 speech coding application에 사용되었다가 지금은 일반적으로 linear predictive analysis technique들을 말하는데 쓰입니다.
2. LPC를 사용하는 이유
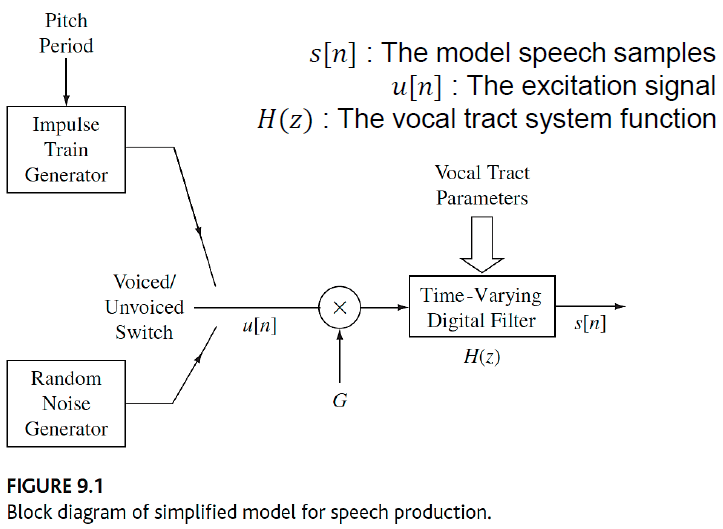
1) Speech Production Model
speech production과정을 아래와 같이 excitation과 vocal tract을 통과하는 과정으로 나누어 나타내줄 수 있습니다. 이때, vocal tract의 formants (공명주파수)에 따라 발생하는 음성 신호가 달라지게 됩니다.
그래서 만약 우리가 이 vocal tract을 digital filter로 나타내고, 이 digital filter의 parameter에 따라 formants가 달라지는 것을 반영하면 말소리를 흉내낼 수 있게 됩니다.
아래의 impulse train은 continuous signal이지만 T 간격으로 값을 가지기 때문에 다른 signal에 곱해주면 T주기로 sampling된 discrete signal을 얻어낼 수 있습니다. 이를 이용해서 CTFT와 DTFT의 관계를 정리해보도록 하겠습니다.
Impulse train (왼) Impulse train을 continuous signal에 곱해 discrete signal로 표현한 모습 (오)
Time-domain에서의 multiplication는 frequency-domain에서 convolution과 같다는 특성이 있습니다. (CTFT / DTFT의 property) 그렇기 때문에 time domain에서 signal x(t)x(t)와 impulse train s(t)s(t)의 multiplication을 CTFT한 것은 각각의 signal을 CTFT해준 후에 convolution해준 것과 같습니다.
식을 보면 1T1T로 scaling된 Xc(jΩ)Xc(jΩ)ΩsΩs 간격으로 반복된다는 것을 알 수 있는데, 잘 와닿지 않기 때문에 그림으로도 확인해보도록 합시다.
continous signal x(t)의 CTFT 결과Impulse train을 CTFT한 결과
time domain에서 signal x(t)x(t)와 impulse train s(t)s(t)의 multiplication을 CTFT한 것은 각각의 signal을 CTFT해준 후에 convolution해준 것과 같기 때문에 Xc(jΩ)Xc(jΩ)는 아래와 같이 나오게 됩니다.
즉 DTFT는 CTFT를 1T1T만큼 scaling 해준 뒤에 일정한 간격 Ω0=2πTΩ0=2πT으로 반복한 것과 같습니다.
음성신호의 생성 과정은 아래의 Speech production model (Source filter model)로 나타냅니다. 그러면 voiced speech signal 와 unvoiced speech signal 과 각각의 vocal tract impulse response는 아래와 같이 식으로 표현해줄 수 있습니다.
위의 식을 통해서 각각의 component signal들이 convolution되어 최종적으로 음성신호로 출력되는 것을 알 수 있습니다.
1. Homomorphic system
Homomorphic system은 우리가 자주 들어본 LTI system에서의 linearity 성질(principle of superposition)을 일반화 시킨 시스템입니다. 기존의 LTI system은 input으로 두 가지 signal이 addition된 형태가 들어오면 output 역시 각 signal의 output의 addition을 출력해주는 특성을 가지고 있습니다.
Homomorphic system의 경우에는 이 superposition 특성을 일반화하여서 input으로 두 가지 signal이 convolution된 형태가 들어오면 output 역시 각 signal의 output의 convolution을 출력해주는 특성을 갖는 시스템을 말합니다.
LTI system와 Homomorphic system
이 Homomorphic system의 중요한 특징이 바로 3개의 homomorphic system을 casecade의 형태로 합쳐 아래의 그림처럼 표현을 할 수 있다는 점입니다. 이때 D∗{⋅}D∗{⋅}은 characteristic system으로 convolution → addition 형태로 출력해주는 시스템이고, 그 inverse system같은 경우에는 반대로 addition → convolution의 형태로 바꿔주는 특성을 가지고 있습니다. 즉 characteristic system에 convolutioned input을 넣어주면 signal의 component들을 addition한 non-linearity한 convoltion 연산을 linearity 연산으로 바꿔줍니다..!!!
Homomorphic deconvolution의 casecade form
그런데 speech signal은 각 component들의 convolution된 signal이니까, 이 characteristic system을 이용하면 신호의 각 성분들을 decompose할 수 있게되는 것입니다. 이때 charateristic system의 output은 complex cepstrum의 합입니다.
2. Cepstrum
Cepstrum은 time-domain에서 frequency-domain으로 변환을 해준 것처럼 frequency-domain에서 time-domain으로의 변환도 가능하다는 것을 보여주기 위해 도입된 개념입니다.
Cepsturm은 아래의 식과 같이 spectrum의 log magnitude를 취한 후 Inverse Fourier Transform을 해주어 구합니다. 그리고 이때 magnitude를 취하지 않고 spectrum의 magnitude만 취한 후 Inverse Fourier Transform을 해주어 구한 것은 complex cepsturm이라고 합니다.
Time-domain representation of speech model for a voiced sound /AE/
그러면 각각의 component들의 complex cepstrum을 addition하면 기존의 신호의 complex cepstrum을 나타낼 수 있습니다. 그럼 addition된 결과물에서 각각의 component의 특성이 잘 보이니까 음성신호 분석에 사용이 가능하다는 것이겠죠? 아래는 각각의 component들의 complex cepstrum입니다.
보시면 아실 수 있듯이 각자 특징이 보입니다. 그렇기 때문에 원래의 synthetic speech의 complex cepstrum을 보았을 때, 각각의 component들의 특징을 알아볼 수 있습니다. 이때 이 포스트에서는 다루진 않았지만, 각각의 component들이 모두 maximum/minimum phase signal이기 때문에 cepstrum은 아래의 오른쪽 그림과 같이 complex cepstrum의 even part로 나타납니다. (이 내용은 길어질 것 같아 따로 포스팅으로 하도록 하겠습니다.)