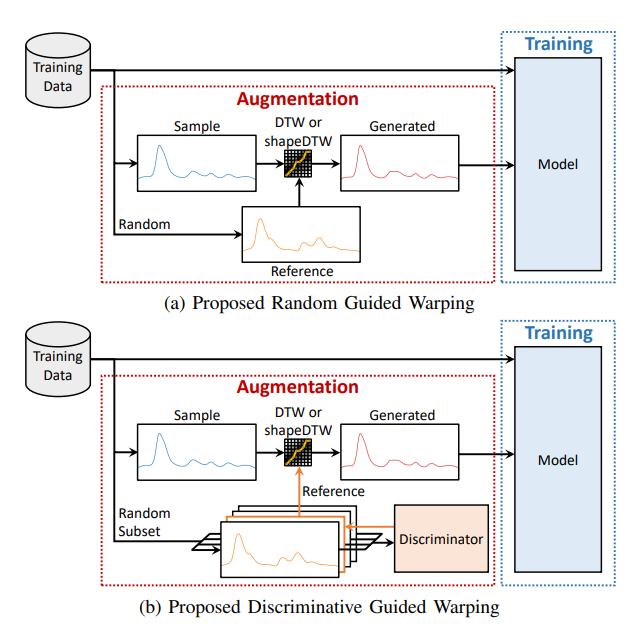
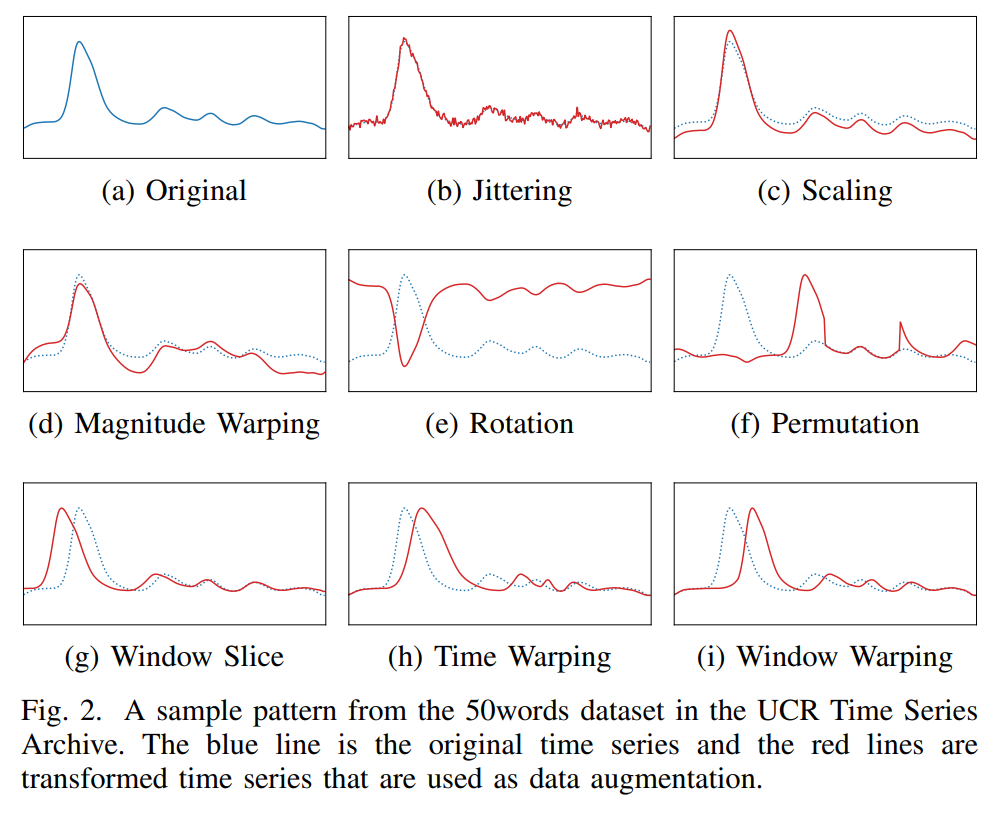
I. Magnitude Warping (MagW)
The magnitude of each time series is multiplied by a curve created by cubic spline with four knots at random magnitudes with mu = 1 and sigma = 0.2.
Python code
def magnitude_warp(x, sigma=0.2, knot=4):
from scipy.interpolate import CubicSpline
orig_steps = np.arange(x.shape[1])
random_warps = np.random.normal(loc=1.0, scale=sigma, size=(x.shape[0], knot+2, x.shape[2]))
warp_steps = (np.ones((x.shape[2],1))*(np.linspace(0, x.shape[1]-1., num=knot+2))).T
ret = np.zeros_like(x)
for i, pat in enumerate(x):
warper = np.array([CubicSpline(warp_steps[:,dim], random_warps[i,:,dim])(orig_steps) for dim in range(x.shape[2])]).T
ret[i] = pat * warper
return ret
# code 출처 https://github.com/uchidalab/time_series_augmentation
1. numpy.random.normal을 사용하여 평균이 mu, 표준편차가 sigma인 Gaussian distribution으로부터 크기가 trial x 6 x sample 인 random sample을 뽑음.

2. time(sample) 갯수를 기준으로 "1"에서 뽑은 값들을 지나는 3차 다항식 형태로 데이터를 생성함. 그리고 각 trial의 channel마다 생성한 curve들을 기존 data와 곱함
II. Time Warping (TimW)
Time warping based on a random smooth warping curve generated by cubic spline with four knots at random magnitudes (\mu = 1 and \sigma = 0.2).
Python code
def time_warp(x, sigma=0.2, knot=4):
from scipy.interpolate import CubicSpline
orig_steps = np.arange(x.shape[1])
random_warps = np.random.normal(loc=1.0, scale=sigma, size=(x.shape[0], knot+2, x.shape[2]))
warp_steps = (np.ones((x.shape[2],1))*(np.linspace(0, x.shape[1]-1., num=knot+2))).T
ret = np.zeros_like(x)
for i, pat in enumerate(x):
for dim in range(x.shape[2]):
time_warp = CubicSpline(warp_steps[:,dim], warp_steps[:,dim] * random_warps[i,:,dim])(orig_steps)
scale = (x.shape[1]-1)/time_warp[-1]
ret[i,:,dim] = np.interp(orig_steps, np.clip(scale*time_warp, 0, x.shape[1]-1), pat[:,dim]).T
return ret
# code 출처 https://github.com/uchidalab/time_series_augmentation
1. numpy.random.normal을 사용하여 Gaussian distribution으로부터 dataset과 크기가 같은 평균이 mu, 표준편차가 sigma인 random sample을 뽑음.
2. time(sample) 갯수를 기준으로 "1"에서 뽑은 값들을 지나는 3차 다항식 형태로 데이터를 생성함. 그리고 각 trial과 channel을 고정후 scaling한 데이터를 numpy.interp를 이용하여 sample points들을 단조롭게 증가하도록 바꿈
'신호처리 > Augmentation' 카테고리의 다른 글
| Time Series Data Augmentation for Neural Networks by Time Warping with a Discriminative Teacher - 논문 공부(1) (0) | 2021.11.26 |
|---|