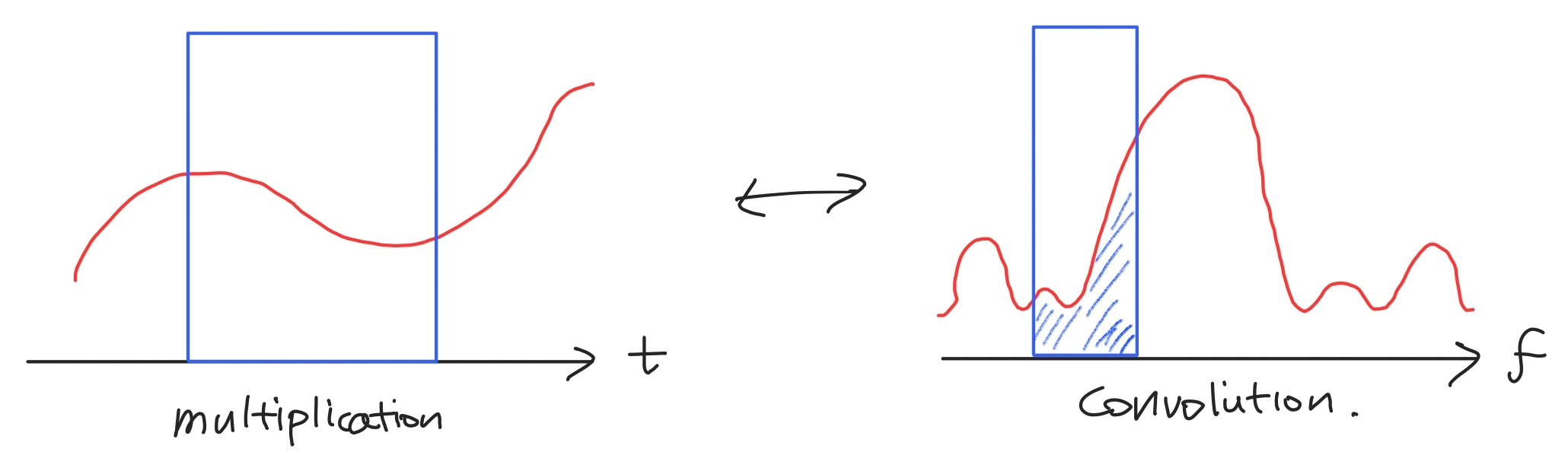1. Gaussian Noise (White Noise) : 정규분포를 따르는 고정 잡음 유형
2. White Noise : 특정 frequency 대역에서 동일한 intensity를 갖는 random signal
3. Background Noise : target으로 하는 소리 외의 주변에서 발생하는 모든 소리
4. Brownian Noise (red noise) : brownian motion(액체/기체에서 나타나는 입자의 random motion)에 의해 생성되는 signal noise.무작위한 변동을 가지면서도 시간이 지남에 따라 어느 정도의 bias 또는 drift를 나타냄.
white noise(좌), white noise vs pink noise(중앙), brownian nosie(우)
Non-Stationary Noise
1. Impulse Noise : 원치 않은 순간적인(impulse) 소리를 포함하는 noise로, 일반적으로 전자기 간섭, 디스크 긁힘, 총격, 폭발, 디지털 동기화 문제로 인해 발생
2. Transient Noise : 문닫는 소리, 자동차 경적 소리 등, 일상에서 짧게 발생되는 noise들
3. Reverberation : 반향은 주변 환경 요소에 계속 반사되면서 시간에 따라 변화하기 때문에 non-stationary noise로 여겨질 수 있음
4. Pink Noise : power spectrum의 밀도가 신호의 frequency에 역비례(1/f)하는 진동수 스펙트럼이 있는 signal. pink noise의각 옥타브 주기는 동일한 양의 노이즈 에너지를 전달함. (생물학계에서 가장 흔한 신호들 중 하나라고 함.)
pink noise(좌)와 white noise(우)의 spectrogram; 세로축은 linear한 frequency 축, 가로축은 시간축 (출처 : 위키백과 'pink noise')
STFT는 특정 짧은 시간 구간을 windowing을 통해 추출해내고 해당 구간 동안에 DFT를 하여 연산을 수행한다.
이때 windowing은 signal을 window와 time domain에서 multiplication을 시키는 과정이다. time domain에서의 multiplication 연산은 frequency domain에서는 convolution 연산과 같다.
여기서 time resolution과 frequency resolution의 관계에 대해 생각해볼 수 있다.
window의 크기를 작게하면 우리는 시간축에 대해 세밀한 분석을 수행해줄 수 있지만, 주파수축에서는 convolution을 수행하는 band가 넓어지게 된다(wide band). 그러면 주파수축에 대해서는 오히려 resolution(분해능)이 떨어지게 된다.
예를 들어 아래와 같은 narrow band와 wide band가 있다고 가정을 해보자.
0
위에서의 해당 시간에 대한 신호의 frequency response가 아래와 같을 때,
time domain에서 window를 수행한 결과(왼)와 해당 signal의 frequency response
narrow band와 wide band에 대한 convolution 연산 결과는 다음과 같이 나타나게 된다.
대충 그려서 그림이 부정확할 수 있어요....
즉 narrow band를 사용하면 frequency domain에서 각 frequency 에 대한 정보를 세밀하게 살릴 수 있게 된다.
아래는 실제 STFT 결과이다. 아래에서도 wide band를 사용했을 때는 time resolution이 좋고, frequency resolution이 떨어져 세로선의 형태가 나타나는 것을 확인할 수 있다. 반대로 narrow band를 사용했을 때는 time resolution이 떨어지고 frequency resolution이 좋아져 가로선의 형태가 나타나는 것을 확인할 수 있다.
같은 fram length를 가질 때, Hamming window의 cutoff frequency가 Rectangular window의 cutoff frequency의 두배이다. 즉 Hamming window(wide band)를 사용해 얻은 결과는 Rectangular window(narrow band)를 사용했을 때보다 frequency resolution이 떨어진다. (Rectangular window는 hamming window에 비해 freqeucncy resolution이 좋음)
하지만 Attenuation 같은 경우에는, Hamming window가 더 강하기 때문에 lobe가 약하게 나타난다. 그렇기 때문에 Rectangular window보다는 Hamming window를 사용했을 때, frequency band 외의 frequency가 연산에 개입이 적게 되기 때문에 error가 비교적 적다. (attenuation이 아주 강해서 lobe가 없는 경우가 noise가 없는 이상적인 상황)
즉, Rectangular window를 사용하면 frequency resolution이 좋다는 장점을 챙길 수 있으나 연산 과정에서 발생하게 되는 noise가 비교적 크고, Hamming window를 사용하면 frequency resolution은 떨어질 수 있으나 noise가 적다는 이점을 가진다.
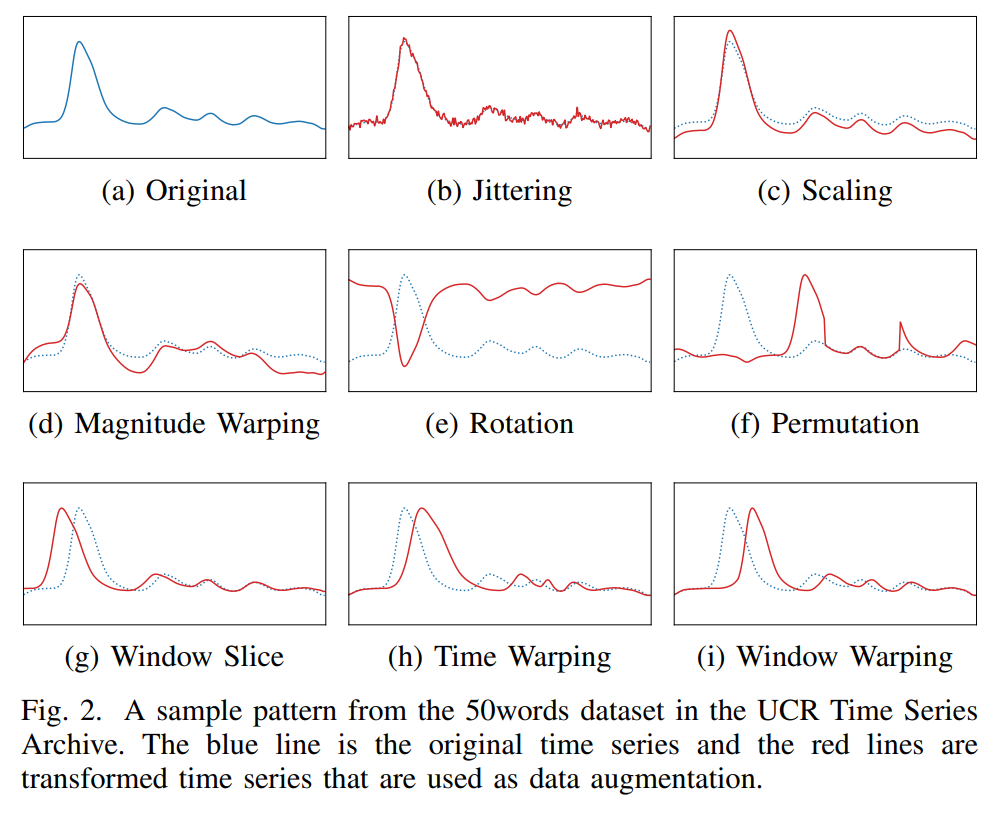
The magnitude of each time series is multiplied by a curve created by cubic spline with four knots at random magnitudes with mu = 1 and sigma = 0.2.
Python code
def magnitude_warp(x, sigma=0.2, knot=4):
from scipy.interpolate import CubicSpline
orig_steps = np.arange(x.shape[1])
random_warps = np.random.normal(loc=1.0, scale=sigma, size=(x.shape[0], knot+2, x.shape[2]))
warp_steps = (np.ones((x.shape[2],1))*(np.linspace(0, x.shape[1]-1., num=knot+2))).T
ret = np.zeros_like(x)
for i, pat in enumerate(x):
warper = np.array([CubicSpline(warp_steps[:,dim], random_warps[i,:,dim])(orig_steps) for dim in range(x.shape[2])]).T
ret[i] = pat * warper
return ret
# code 출처 https://github.com/uchidalab/time_series_augmentation
1. numpy.random.normal을 사용하여 평균이 mu, 표준편차가 sigma인 Gaussian distribution으로부터 크기가 trial x 6 x sample 인 random sample을 뽑음.
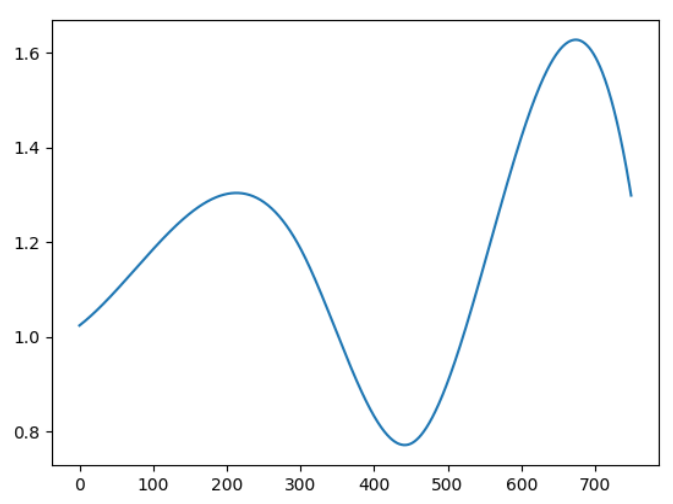
[figure 1]
2. time(sample) 갯수를 기준으로 "1"에서 뽑은 값들을 지나는 3차 다항식 형태로 데이터를 생성함. 그리고 각 trial의 channel마다 생성한 curve들을 기존 data와 곱함
[figure 2]
[Figure 3. Magnitude Warping 결과]
II. Time Warping (TimW)
Time warping based on a random smooth warping curve generated by cubic spline with four knots at random magnitudes (\mu = 1 and \sigma = 0.2).
Python code
def time_warp(x, sigma=0.2, knot=4):
from scipy.interpolate import CubicSpline
orig_steps = np.arange(x.shape[1])
random_warps = np.random.normal(loc=1.0, scale=sigma, size=(x.shape[0], knot+2, x.shape[2]))
warp_steps = (np.ones((x.shape[2],1))*(np.linspace(0, x.shape[1]-1., num=knot+2))).T
ret = np.zeros_like(x)
for i, pat in enumerate(x):
for dim in range(x.shape[2]):
time_warp = CubicSpline(warp_steps[:,dim], warp_steps[:,dim] * random_warps[i,:,dim])(orig_steps)
scale = (x.shape[1]-1)/time_warp[-1]
ret[i,:,dim] = np.interp(orig_steps, np.clip(scale*time_warp, 0, x.shape[1]-1), pat[:,dim]).T
return ret
# code 출처 https://github.com/uchidalab/time_series_augmentation
1. numpy.random.normal을 사용하여 Gaussian distribution으로부터 dataset과 크기가 같은 평균이 mu, 표준편차가 sigma인 random sample을 뽑음.
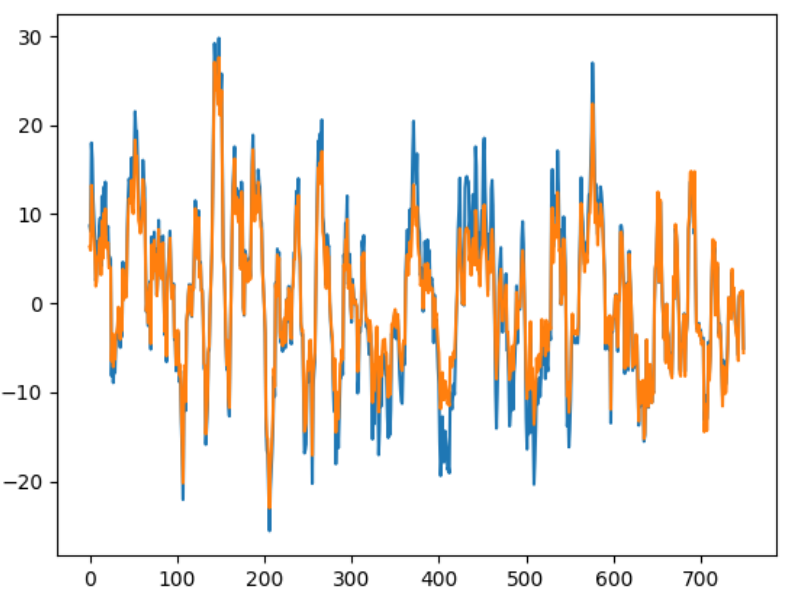
[figure 4]
2. time(sample) 갯수를 기준으로 "1"에서 뽑은 값들을 지나는 3차 다항식 형태로 데이터를 생성함. 그리고 각 trial과 channel을 고정후 scaling한 데이터를 numpy.interp를 이용하여 sample points들을 단조롭게 증가하도록 바꿈
인공 신경망이 보편화 되고, 많은 분야에 걸쳐 최첨단 benchmark를 설정하고 있다. 최근에 인공 신경망이 성공하고 있는 이유는 data의 가용성과 이를 서포트해주는 하드웨어의 성장에 덕분이다. 많은 양의 데이터는 generalization과 많은 machine learning model들의 accuracy를 높여준다.
하지만 image 영역에서 time series dataset은 비교적 매우 작다. 따라서 현대의 machine learning method들의 잠재력을 많이 사용하기 위해서는 time series classification data가 필요하다.
2. Augmentation이란
이 문제를 해결하기 위한 한가지 방법이 data augmentation을 사용하는 것이다. Augmentation은 흔한 data-space solution으로, 인조적인 pattern들을 사용해 training dataset을 늘려 machine learning model의 generalization ability를 상승시킨다. 또한 overfitting을 줄이고 model의 decision boundary를 확장시킨다.
Image를 위한 Data augmentation은 특히 신경망과 결합되어 잘 연구된 분야이며, Image classification 분야에서는 대부분 일반적인 관행이 되었다.
3. Time Series data에서의 augmentation
확립된 Time series augmentation method들이 상대적으로 적고, 대부분 일반적으로 image recognition의 영향을 받았기다. 때문에 일반적으로 단순한 transformation(jittering, scaling, rotation, etc.)에 의존한 방법들이다. Time series는 image와 다른 property들을 갖기 때문에 이 방법들은 모든 time series에 적용 가능하지 못할 수 있다.
몇가지 time series의 특정한 data augmentation 방법(magnitude warping, time warping)들이 존재하는 반면, 근본적인 data의 pattern이 있다는 가정하에 여전히 random trainsformations이다.
4. 제안
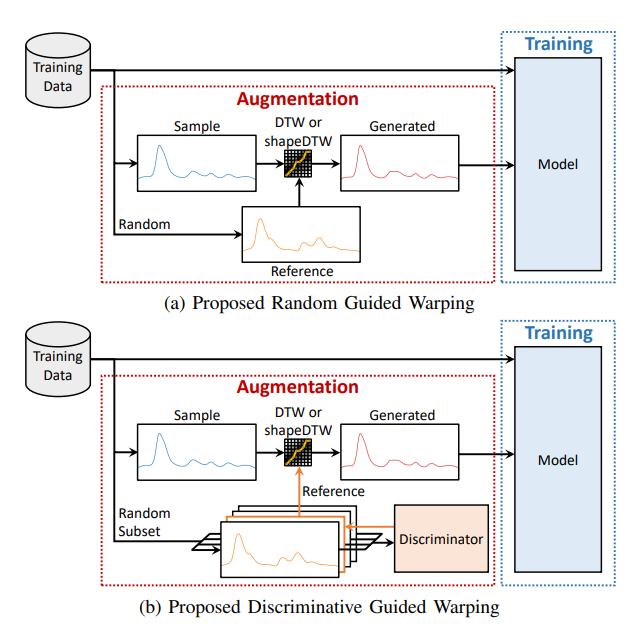
Augmentation에 기반을 둔 새로운 pattern mixing의 사용을 제한한다. 두 time series 사이의 feature를 맞추기 위해 DTW(Dynamic Time Warping)가 사용된다. 그리고 element-wise alignment 대신 shapeDTW를 사용함으로써 dynamic warping이 더욱 향상될 수 있음을 입증한다.
더 나아가, 어떤 reference time series를 선택하느냐에 대한 의문이 드는데, 최고의 전략이 필연적이지 않다는 것을 보여주고, 선택을 위한 discriminator 사용 방법의 novel method를 제안한다.
Discriminator에 의해 선택된 reference pattern을 discriminative teacher하 하고, 같은 class의 pattern과 다른 class의 patten 사이의 최대 거리를 가진 bootstrap set 내에서 sample을 찾아 결정한다. 이 논문에서는 작은 batch의 무작위 sample에서 간단한 가장 가까운 centroid classifier를 사용한다.
Random teacher 보다는 discriminative teacher 사용하면 quided warping이 classifier를 지원하는 pattern을 고르도록 할 수 있다.