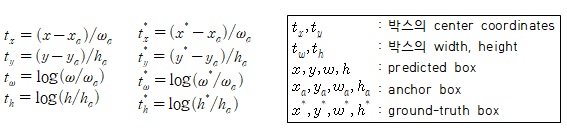while (1)
{
ADC_Receive(adc_array); // ADC값을 받아온다.
if(button == 1) // 버튼을 한 번 누르면 ADC 최대 최소값 받음
{
PORTA = 0x55;
for(int i = 0; i < 8; i++)
{
if(adc_array[i] > adc_max[i]) adc_max[i] = adc_array[i];
if(adc_array[i] < adc_min[i]) adc_min[i] = adc_array[i];
}
}
else if(button >= 2) // 버튼을 한 번 더 누르면
{
PORTA = ~(1 << flag);
Normalization(adc_array, adc_max, adc_min); // 정규화
line_s = 0;
for(int i = 0; i < 8; i++)
{
UART1_Transmit(line[i] + 48); // 각 센서가 검은줄 위에 있는지 0/1로 uart로 출력
line_s += line[i]; // 검은줄 위에 있는 수발광 센서의 수
}
if((sigma_L + sigma_R) != 0) uturn = MOTOR_Direction((sigma_R + sigma_L), line_s, uturn); // 가중치 가 0이 아닐 경우 모터 방향 변경
//uturn = MOTOR_Direction((sigma_R + sigma_L), line_s, uturn); // 수정
// 문제점 1. 가중치가 0일 경우를 제외하였기 때문에 직진을 바르게 하지 못했음.
}
UART1_Transmit(' '); // 띄어쓰기
Weighted_Data_Processing(); // 가중치
UART1_Transmit(13); // uart 줄넘김
}
예전에는 1년에 한 번꼴로 병원에 방문하여 정기검진을 통해서만 내 몸의 변화를 볼 수 있었지만, 최근 몇 년 사이 우리 주변에 붙어있는 Mobile device들을 통한 정보수집이 편리해지면서 병원 밖에서 이루어지는 Health care 역시 중요해졌다. 그리고 인류의 기대 수명이 증가하면서 ‘건강’의 대표적인 키워드는 ‘장수’가 아닌 ‘건강수명’으로 변화하게 되었다.
* 건강수명 : 평균수명에서 질병이나 부상으로 인하여 활동하지 못한 기간을 뺀 기간
이에 따라 지속적인 건강 관리에 사람들이 관심을 가지게 되었고, 그에 필요한 아이템들의 수요가 증가하게 되었다. 하지만, 많은 사람들이 제대로 운동을 배우고 지속적하는 것을 버거워해 작심삼일로 끝나고는 한다. 이를 위한 해결책으로 미국 ‘하버드 헬스’에서 소개한 전문가의 조언들을 아래에 간추려 놓았다.
운동의 재정의 : 운동의 핵심은 심박수가 올라가는 것, 운동에 편하게 접근하자.목표조절 : 매일 21분씩만 운동해도 WHO의 일주일 권장 시간(150분 이상)에 도 달할 수 있다. 목표를 낮춰 조금이라도 운동을 하도록 노력해보자.동료 : 함께 운동할 수 있는 동료가 있으면 꾸준히 할 수 있다.
나는 이 중 ‘운동을 재정의’에 집중하여, 운동을 시작하는 진입장벽을 낮추기 위해 Health Manager 프로그램을 만들어보고자 하게 되었다.
현재 Play Store나 App Store에 나와있는 어플리케이션 중에서 카메라는 활용된 경우는 많지 않고 일정 시간 간격으로 카운트를 해주는데 그쳐 피드백이 이루어지지 않는다는 문제점이 있다고 생각했다. 그래서 하나의 카메라를 통해 운동을 인식하여 자동 카운트 해주고, 운동 속도에 대한 피드백을 계속해서 해주는 방식으로 개선을 하는 데에 목표를 잡았다.
지금은 학부생 수준에서의 프로젝트기에 시중에서 사용하기에는 부족하겠지만, 데이터 축적이나 나아가서는 이 프로젝트에서 몇가지 영상처리와 딥러닝 네트워크와 모델들을 공부해 이용해 보고, Digiter Health Care 분야에 활용할 수 있는 방법을 모색해보는 기회를 만들고자 한다.
Open Pose를 이용한 Key Point Detection & Skelton 생성 https://www.arxiv-vanity.com/papers/1812.08008/
특히나 지난 학기에는 Open Pose라는 Model의 Key Point Detection한 결과를 이용했다면, 이번에는 Model을 구현해보면서 Object detection과 Tracking 원리를 이해하고, 홈트레이닝에서 하는 주된 운동 중 쉽게 할 수 있는 하체운동인 스쿼트의 측정을 목표로 잡아 이번 프로젝트를 실현해보겠다.
2. 목표
카메라로 스쿼트의 앉은 자세와 선자세를 구별해서 스쿼트 개수를 자동으로 (음성으로) 세주는 시스템을 구현한다.
이 프로젝트에서는 사람 한 명의 동작을 추정하는 것이 중요하기 때문에 사람을 먼저 인식한 후에 key points를 추출하는 Top-down(하향식) 방법을 이용할 계획이다.
먼저 Segmentation을 통해 영상의 이미지에서 사람이 있는 영역만 RoI로 지정을 해줄 것이다.
보통 Human key point tracking을 할 때, CNN(Convolutional Neural Networks)을 기반으로 한 특징 추출 model을 이용하는데, 프로젝트의 목표가 pose estimation system을 기반으로 하기 때문에 Mask R-CNN을 사용할 것이다.
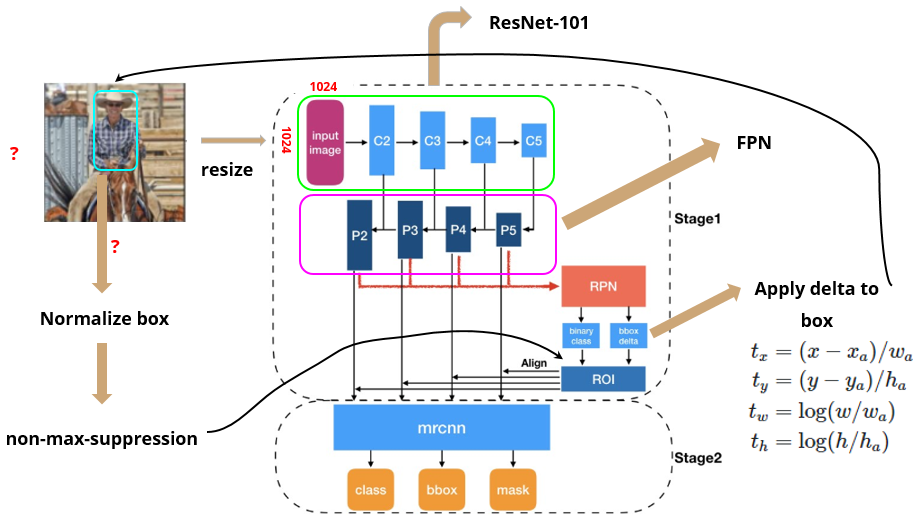
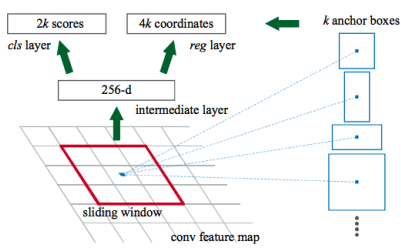
여기서 Mask R-CNN은 하향식 keypoint estimation model로 ResNet을 확장시킨 framwork를 말한다. 표준적인 기반이 CNN²인 ResNet으로 구성되며 이미지의 특징을 추출하는데 사용된다. Mask R-CNN의 구조는 다음과 같다.
MASK R-CNN의 네트워크 구조 https://ganghee-lee.tistory.com/40
① Resize Input image
기존 Segmentation을 만들어진 Mask R-CNN³에서는 backcone으로 ResNet-101을 사용하는데 ResNet 네트워크에서는 input image의 size가 800~1024일 때 성능이 좋다고 알려져 있다. 따라서 이미지를 binear interpolation⁴을 사용해 resize 해주고 네트워크 input size(1024 x 1024)에 맞게 나머지 값들은 zero padding⁵으로 채워준다.
② BackboneResNet-101
Mask R-CNN에서는 Backbone으로 ResNet-101 모델을 사용한다.
모델의 layer가 너무 깊어질수록 오히려 성능이 떨어지는 현상이 발생하는데, 그 이유가 gradient vanishing/exploding 문제 떄문에 학습이 잘 이루어지지 않기 때문이다.
여기서 gradient vanishing이란 layer가 깊어질수록 미분을 점점 많이 하기 때문에 backpropagation을 해도 앞의 layer일수록 미분값이 작아져 그만큼 output에 영향을 끼치는 weight 정도가 작아지는 것을 말한다. 이 문제를 해결하기 위해 고안된 것이 ResNet이다.
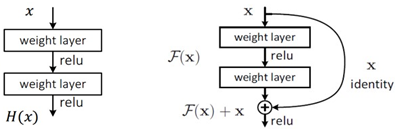
ResNet이전의 이미지 classification과 같은 문제의 경우 x에 대한 타겟값 y는 사실 x를 대변하는 것으로 y와 x의 의미가 같게끔 mapping해야 한다. 즉, H(x)-x 를 최소화하는 방향으로 학습을 진행해야 하는 것이다.
이 때, F(x) = H(x) - x를 잔차라고 하며 이 잔차를 학습하는 것을 Residual learning이라 한다.
위의 두 가지 그림을 보자. 왼쪽 그림처럼 네트워크의 output이 x가 되도록 한다. 하지만 오른쪽 그림은 마지막에 x를 더해주어 네트워크의 output이 0이 되게끔 하는 것을 볼 수 있다. ResNet은 오른쪽 그림과 같이 mapping해서 최종 output이 x가 되도록 학습한다.
네트워크는 0이 되도록 학습시키고 마지막에 x를 더해서 H(x)가 x가 되도록 학습하면 미분을 해도 x자체는 미분값 1을 갖기 때문에 각 layer마다 최소 gradient로 1은 갖도록 한 것이다.
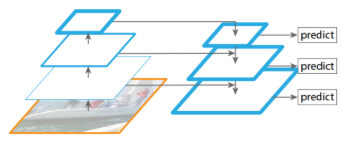
③ FPN (Feature Pyramid Network)
이미지 출처 : FPN https://ganghee-lee.tistory.com/40
마지막 layer의 feature map⁶에서 점점 이전의 중간 feature map들을 더하면서 이전 정보까지 유지할 수 있도록 한다. 이렇게 함으로써 모두 동일한 scale의 anchor를 생성하게 되고, 작은 feature map에서는 큰 anchor를 생성하여 큰 object를, 큰 feature map에서는 다소 작은 anchor를 생성하여 작은 object를 detect할 수 있도록 설계되었다.
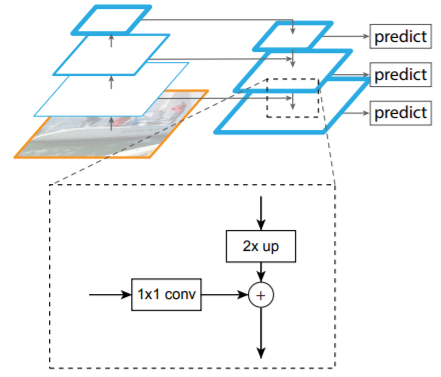
특히 마지막 layer에서의 feature map에서 이전 feature map을 더하는 것은 아래와 같이 Upsampling⁷을 통해 이루어진다.
이미지 출처 : FPN https://ganghee-lee.tistory.com/40
2배로 upsampling을 한 후 이전 layer의 feature map을 1x1 Fully convolution 연산을 통해 filter개수를 똑같이 맞춰준 후 더함으로써 새로운 feature map을 생성한다.
④ RPN (Region Proposal Network)
RPN의 input 값은 이전 CNN 모델에서 뽑아낸 feature map인데, 각 feature map에서 1개 scale의 anchor를 생성하므로 결국 각 pyramid feature map마다 scale 1개 x ratio 3개 = 3개의 anchor를 생성한다. Region proposal을 생성하기 위해 feature map위에 nxn window를 sliding window를 시키면서 object의 크기와 비율이 어떻게 될지 모르므로 k개의 anchor box를 미리 정의해놓는다.
여기서 나온 anchor box가 bounding box가 될 수 있기때문에 미리 box 모양 k개를 정의해놓는 것이다. (위의 사진에서는 가로세로길이 3종류 x 비율 3종류 = 9개의 anchor box를 이용한다.)
여기서 나온 anchor box를 이용하여 classification과 bbox regression(delta)을 먼저 구하고 이 값에 anchor 정보를 연산해서 원래 이미지에 대응되는 anchor bounding box 좌표값으로 바꿔주게 된다.
⑤ NMS (Non-maximum-suppression)
원래 이미지에 anchor 좌표를 대응시킨 후에는 각각 normalized coordinate로 대응시킨다. (FPN에서 이미 각기 다른 feature map 크리를 갖고 있기 때문에 모두 통일되게 정규좌표계로 이동시키는 과정) 그러면 결과는 아래의 왼쪽 사진과 같이 나타난다.
NMS 처리 전후 / 이미지 출처 : https://ganghee-lee.tistory.com/40
각 object마다 대응되는 수십개의 anchor 중에서 장 classification score가 높은 anchor를 제외하고 다른 anchor들을 지운다.
NMS알고리즘은 anchor bounding box들을 score순으로 정렬시킨 후 score가 높은 bounding box부터 다른 bounding box와 IoU(Intersection Over Union)를 계산한다.
이때 IoU가 해당 bounding box와 0.7이 넘어가면 두 bounding box는 동일 object를 detect한 것이라 간주하여 score가 더 낮은 bounding box는 지우는 식으로 동작한다. 최종적으로 각 객체마다 score가 가장 큰 box만 남게되고 나머지 box는 제거하게 되면 오른쪽 사진과 같이 하나의 bounding box만 남게 되는 것이다.
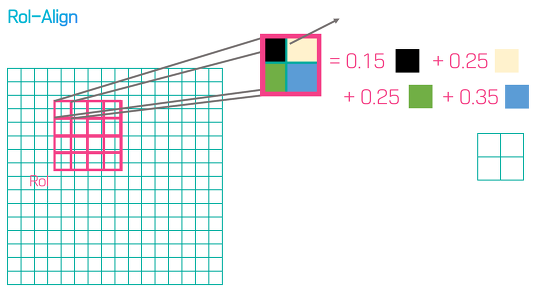
⑥ RoI align
RoI pooling을 진행했을 때 발생하는 위치정보 왜곡 문제를 해결하기 위해 align을 이용한다. align은 각각의 RoI 영역에 대해 4개의 sample point에 대해 bilinear interpolation을 수행하고, 그 결과에 대해 max 또는 average로 합치는 것을 말한다.
RoI align / 이미지 출처 : https://ganghee-lee.tistory.com/40
Simple Baselines for Human Pose Estimation and Tracking, Microsoft Research Asia, University of Electronic Science and Technology of China (21 Aug 2018)
Detect-and-track: Efficient Pose Estimation in Videos, The Robotics Institute, Carnegie Mellon University (2 May 2018)
Deep High-Resolution Representation Learning for Human Pose Estimation, University of Science and Technology of China (25 Feb 2019)
전자의수족에 관심이 있어 종종 관련자료들을 찾아보고는 했습니다. 외부상황을 인식해 장갑형태의 로봇손, 절단부위의 잔존근육에서 발생하는 미세한 생체신호(근전도 신호)를 이용하여 컨트롤을 하는 등의 기술 등을 볼 수 있었습니다. 하지만 모든 사람들의 팔 상하단, 손바닥크기 손가락 마디들의 길이가 같지 않듯이, 사람들의 움직임 역시 일반화할 수 없을 것이라는 의문이 들었습니다. 그리고 한 사람의 팔의 움직임을 가장 유사하게 구사할 수 있는 것은 신체 비율이 비슷한 반대쪽 팔이지 않을까 싶은 생각을 가지게 되었습니다. 이에 영상처리를 이용하여 왼팔의 움직임을 읽어 그 정보를 로봇팔(왼쪽)로 전송해 오른팔과 움직임과 비슷하게 구현해내자는 목표를 설정하게 되었습니다.
2. 목표
- 카메라는 한 대만 사용
Open Pose가 한 프레임을 받아오는 시간이 결코 짧지 않기 때문에, 한 대를 사용하는 것이 효율적이라고 생각했습니다.
- 주먹 쥐었다 펴기
손가락을 5개의 모터를 이용해 다 제어하기에는 하드웨어 무게가 감당이 되지 않을 것 같았습니다. 그래서 서보모터 하나만 사용하여 주먹을 쥐었다 펴는 동작을 구현하고자 했습니다.
- 팔꿈치 아래인 팔 하안부 동작 구현
팔꿈치 부분의 모터 2개를 연결해주어야 아래의 1. 팔을 돌리는 동작 / 2. 팔을 구부리는 동작 을 구현하고 싶었습니다.
팔 동작
하지만 팔을 돌리는 동작의 경우 z축을 회전시켜 똑같이 구현하려 하게 된다면, 카메라 두 대가 필요했습니다. 그래서 오른쪽의 그림과 같이 모터를 수직으로 연결하는 방식으로 프로젝트를 진행해보기로 결정하게 되었습니다.
3. Hardware Architecture
하드웨어 구상
손 부분의 3D 모델링은 Thingivers에서 가져왔고 그 외 부분 모델링은 INVENTOR를 사용했습니다.
서보모터를 제어하기 위해서는 20ms의 간격으로 1~2ms 폭의 펄스(사각파)를 생성 해야 하며, 펄스의 폭에 의해서 각도가 정해집니다. 구동 범위가 0~180°인 서보모터의 경우 아래와 같이 최소값을 1.0ms 최대값을 2.0ms로 잡고 백분위를 이용해 계산하여 제어를 할 수 있습니다.
이번 프로젝트에서 사용하는 RDS5160의 경우에는 360° 구동이 가능한 모터이기 때문에 0°를 1.0ms, 그리고 360°를 2.0ms로 계산하면 됩니다.
2. 360도 서보모터 제어하기
서보모터는 Timer 3의 Fast PWM mode를 이용해 주기를 맞춰주었습니다.
[main.c]
#include "mcu_init.h"
int cnt = 0;
int adc_array[8] = {0, };
int i = 0;
float servo1 = .080;
float servo2 = .075;
int duty1, duty2;
// duty 2.5~12.5
int num1 = 0;
int num2 = 0;
char a = 13;
int flag;
int number = 0;
int sign = 0;
// UART 통신
ISR(TIMER2_OVF_vect)
{
cnt++;
TCNT0 = 131; // 4ms
a = UART1_Receive();
if(a == ',')
{
if(sign == 1) num1 = -num1;
flag = 1; sign = 0;
}
else if(a == 13)
{
if(sign == 1) num2 = -num2;
flag = 2; sign = 0;
}
if(flag == 0) Receive_num1();
else if(flag == 1) Receive_num2();
else if(flag == 2)
{
UART1_TransNum(num1);
UART1_Transmit(',');
UART1_TransNum(num2);
UART1_Transmit(13);
if((num1 >= 40) && (num1 <= 110)) servo1 = (double)num1 / 1000;
if((num1 >= 35) && (num1 <= 105)) servo2 = (double)num2 / 1000;
num1 = 0; num2 = 0; flag = 0;
}
MOTOR_Direction(servo1, servo2);
if(cnt == 25) // 100ms
cnt = 0;
}
void Receive_num1() // 첫번째 수를 입력받는다.
{
num1 *= 10;
number = a - 48;
if(a == '-') sign = 1;
if((number >= 0) && (number <= 9)) num1 += number;
}
void Receive_num2() // 두번째 수를 입력받는다.
{
num2 *= 10;
number = a - 48;
if(a == '-') sign = 1;
if((number >= 0) && (number <= 9)) num2 += number;
}
ISR(INT0_vect) // 인터럽트 0번 발생시 1번 서보모터 duty비 80%
{
servo1 = .080;
}
ISR(INT1_vect) // 인터럽트 1번 발생시 2번 서보모터 duty비 75%
{
servo2 = .075;
}
int main(void)
{
UART1_INIT();
Timer2_INIT();
BUTTON_INIT();
SERVO_MOTOR_INIT();
ADC_INIT();
sei();
while(1);
}
터미널을 통해 두 모터의 duty값 전송
서보모터가 UART 통신을 통해 수신받은 값으로 잘 움직이는 것을 확인할 수 있었습니다. 그러나, 속도는 조절할 수 없다는 단점 때문에 움직임이 뚝뚝 끊겨보이는 문제가 생겼습니다.
이 문제는 다음과 같이 서보모터가 목표값에 도달할 때까지 제어주기마다 1씩 OCR값을 변화시켜주는 방법으로 해결할 수 있었습니다.
애초에 조립이 제대로 되지도 않았고, 생각을 잘못했던 게 구조상 실을 당겼다 놓으면 다시 손이 펴져야 하는 구조인데, 탄성이 없으니 돌아올리가 없었습니다.
그래서 무엇을 사용할 지 고민을 하다가 몰드용 액상 실리콘을 사용하게 되었습니다. 실리콘을 구매하는 것 자체가 처음인지라, 인터넷을 찾아보고 구매하고 직접 사용해보면서 경도를 맞춰나갔습니다.
실리콘을 마디에 넣어 사용한 모습
위의 사진은 아래 경도 25의 실리콘을 사용하였을 때의 모습입니다. 움직임이 부드럽지만, 탄성이 떨어져 사용에는 부적합하다 판단했습니다.
다음으로는 경도 40의 실리콘을 사용하였으나, 역시나 탄성이 부족한 느낌이 들어 사용하기에는 어렵다는 생각이 들었습니다.
마지막으로 선택하게 된 게 퍼티형 실리콘이였습니다. 액상실리콘의 경화시간이 너무 긴데다가 시간이 얼마 남지 않아 내린 결론이었습니다. (경도 60정도의 실리콘을 사용하고 싶었으나 구매처를 찾지 못했습니다.)
결과적으로는 실리콘 퍼티가 가장 적당하다고 생각은 들었으나, 신율이 작은 것인지, 너무 많이 늘어나면 부서지는 모습을 보여서 아쉬웠습니다. 판매처에 경도와 경화시간 외에 다른 정보들이 없어 고려하지 못했으나, 경도보다는 신율와 수축율을 중점적으로 고려했으면 더 좋았을거라는 아쉬움이 남았습니다.